

DeepSeek創始人梁文鋒
近期,中國人工智能公司深度求索(DeepSeek)發布的DeepSeek-R1模型轟動全球,使用極低的成本實現了匹敵美國頂級AI模型的效果,得到從業者的廣泛稱讚。許多研究人員、投資者和西方媒體感嘆,中國AI模型令矽谷震驚,甚至可能改變大模型的研發規則。
隨著DeepSeek爆火,其創始人梁文鋒也受到公眾關注。作為一位17歲考入浙江大學、在量化投資和AI領域均取得驚人成就的“學霸”,梁文鋒卻始終保持低調,很少拋頭露面。許多人好奇,這位低調的85後創業者究竟是如何取得成功。
用數學和AI進行量化投資
公開資料顯示,梁文鋒1985年出生於廣東省湛江市。2002年,17歲的梁文鋒考入浙江大學電子信息工程專業,並在2010年獲得信息與通信工程碩士學位。
在校期間,他對金融市場產生了濃厚興趣。特別是在2008年全球金融危機爆發後,他曾帶領團隊使用機器學習技術分析市場數據,嘗試實現全自動量化交易。這一經歷為梁文鋒積累了實踐經驗,也為他日後的職業生涯奠定了堅實的基礎。
畢業後,梁文鋒首先進入了金融領域。2013年,他與浙大同學徐進共同創立了杭州雅克比投資管理有限公司,並在2015年成立了杭州幻方科技有限公司,致力於通過數學和AI進行量化投資。
2016年,幻方量化推出首個基於深度學習的交易模型,並開始將GPU引入計算交易倉位。在此之後,梁文鋒不斷擴大AI算法研究團隊,將AI技術深度融入量化策略,逐步取代傳統模型。2017年,幻方宣稱實現投資策略全面AI化。2018年,幻方正式確立以AI為核心的發展戰略。
但隨著業務的快速擴展,計算資源不足的問題逐漸顯現。2019年,梁文鋒帶領團隊自主研發了“螢火一號”訓練平台。2020年開始,總投資近2億元、搭載了1100張GPU的“螢火一號”正式投入運作。2021年,幻方投入10億元建設“螢火二號”。
幻方量化在2018年首次獲得私募金牛獎,這是中國私募證券領域的最高獎項。2019年,梁文鋒在當年的金牛獎頒獎儀式上發表了主題演講《一名程序員眼里中國量化投資的未來》,這是他少有的公開發言。
當時,梁文鋒在演講中表示,“量化投資的未來,是用技術讓市場更有效率”。
在AI領域一鳴驚人
2023年,梁文鋒宣布正式進軍通用人工智能(AGI)領域,創辦了深度求索(DeepSeek)。據報道,DeepSeek包括創始人梁文鋒在內,僅有139名工程師和研究人員。相比之下,開發ChatGPT的OpenAI有1200名研究人員,開發Claude模型的Anthropic則有500多名研究人員。
雖然團隊規模不大,DeepSeek在此後一年多里取得了令人矚目的成果。2024年5月,DeepSeek發布DeepSeek-V2模型,憑借創新的模型架構和性價比引發關注。DeepSeek-V2的API定價為每百萬tokens輸入1元、輸出2元,價格僅為美國OpenAI GPT-4 Turbo的百分之一。
DeepSeek解釋稱,DeepSeek-V2采用了創新的架構,例如注意力機制方面的MLA(多頭潛在注意力)和前饋網絡方面的DeepSeekMoE架構等,以實現具有更高經濟性的訓練效果和更高效的推理。
據澎湃新聞報道,DeepSeek-V2的出現一度引發國內的大模型“價格戰”,百度、阿里、字節跳動等大廠紛紛宣布大模型產品降價。對此,梁文鋒在接受媒體采訪時表示,DeepSeek無意成為行業鮎魚,低價背後是希望算力普惠。
去年12月26日,DeepSeek-V3模型發布,引發科技行業高度關注。DeepSeek網站發布的信息顯示,DeepSeek-V3多項評測成績超越了Qwen2.5-72B和Llama-3.1-405B等其他開源模型,甚至可以與GPT-4o、Claude 3.5-Sonnet等頂級閉源模型一較高下。
更引人注目的是,DeepSeek-V3使用的成本和算力極低,僅使用2048顆算力稍弱的英偉達H800 GPU,成本約為557.6萬美元。相比之下,OpenAI的GPT-4o訓練成本高達7800萬美元。這意味著,DeepSeek-V3以十分之一的成本實現了足以與GPT-4o較量的水平。
今年1月20日,DeepSeek進一步取得突破,正式發布DeepSeek-R1模型。該模型在數學、代碼、自然語言推理等任務上,性能比肩OpenAI o1正式版。該模型在後訓練階段大規模使用強化學習(RL)技術,在僅有極少標注數據的情況下,極大提升了模型推理能力。
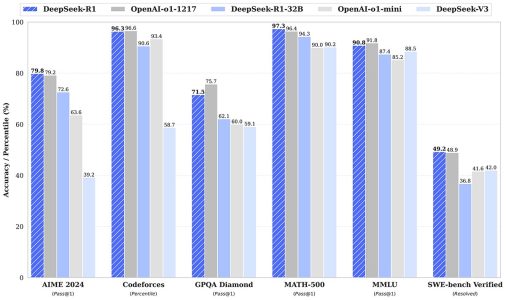
DeepSeek-R1、OpenAI-o1-1217和DeepSeek-V3的性能比較 DeepSeek微信公眾號
這一系列成就震動全球科技行業。美國OpenAI創始成員之一安德烈·卡帕西(Andrej Karpathy)在社交媒體上稱讚:“DeepSeek在有限資源下展現了驚人的工程能力,它可能重新定義大模型研發的規則。”
矽谷知名風險投資家馬克·安德森(Marc Andreessen)將DeepSeek-R1的發布與美國總統特朗普入主白宮相提並論,他稱讚這是“最令人驚嘆的突破之一,給世界的一份意義深遠的禮物”。
DeepSeek的成功與梁文鋒在團隊管理和技術研發上的獨特策略有著密切的關系。他組建了一支由本土年輕程序員組成的團隊,不依賴海歸或高級技術專家,團隊成員多為應屆畢業生或工作經驗不超過5年的年輕人。
梁文鋒曾向媒體坦言,團隊“並沒有什麽高深莫測的奇才,都是一些Top高校的應屆畢業生、沒畢業的博四、博五實習生,還有一些畢業才幾年的年輕人”。他認為,“創新需要擺脫慣性,經驗有時會成為包袱。”
低調的“技術理想主義者”
從應用AI進行量化投資,到投身AI大模型研發,驅動梁文鋒的卻並不是來自商業方面的理由。他在有限的幾次媒體采訪中坦言:“幻方的主要班底里,很多人是做人工智能的。當時我們嘗試了很多場景,最終切入了足夠覆雜的金融,而通用人工智能可能是下一個最難的事之一,所以對我們來說,這是一個怎麽做的問題,而不是為什麽做的問題……如果一定要找一個商業上的理由,它可能是找不到的,因為劃不來。”
他表示,“很多人會以為這里邊有一個不為人知的商業邏輯,但其實,主要是好奇心驅動……對AI能力邊界的好奇。”
DeepSeek一直堅持開源路線,主動向全球開發者分享了核心技術成果。在一些業內人士看來,梁文鋒其實是一位低調的“技術理想主義者”。
去年,梁文鋒在接受媒體采訪時表示,在顛覆性的技術面前,閉源形成的護城河是短暫的。即使OpenAI閉源,也無法阻止被別人趕超。“開源更像一個文化行為,而非商業行為。給予其實是一種額外的榮譽。一個公司這麽做也會有文化的吸引力。”
梁文鋒認為,隨著經濟發展,中國也要成為貢獻者:“我們已經習慣摩爾定律從天而降,躺在家里18個月就會出來更好的硬件和軟件。Scaling Law(縮放定律)也在被如此對待。但其實,這是西方主導的技術社區一代代孜孜不倦創造出來的,只因為之前我們沒有參與這個過程,以至於忽視了它的存在。”
他當時還表示,中國AI不可能永遠處在跟隨的位置,“很多國產芯片發展不起來,也是因為缺乏配套的技術社區,只有第二手消息,所以中國必然需要有人站到技術的前沿。”



